I have needed to stress test a component inside a physical server – this time it was CPU and I’d like to share my method here. I have done a Memory Stress Test using a Windows VM in a previous article. I will be using a Windows VM again, but this time it will be Windows Server 2012 Standard Edition that can handle up to 4TB Memory and up to 64 Sockets containing 640 logical processors – a very nice bump from Windows Server 2008 R2 Standard that had a Compute configuration maximum of 4 sockets and 32 GB RAM.
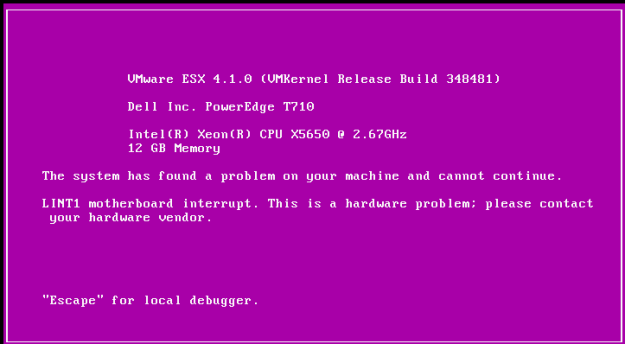
The host has crashed several times into a PSOD with Uncorrectable Machine Check Errors. From the start I had a hunch that the second Physical CPU or a System Board are faulty – but these were replaced already and the host has crashed yet again. I have taken a closer look at the matter and went to stress thest this ill host’s CPUs. Continue reading