One night we had a situation on our remote site that was running ESX 4.1.0 on a DELL PowerEdge T710 Server. It went to PSOD and then the RAID controller stated that it was unable to boot. The screen captures we got were:
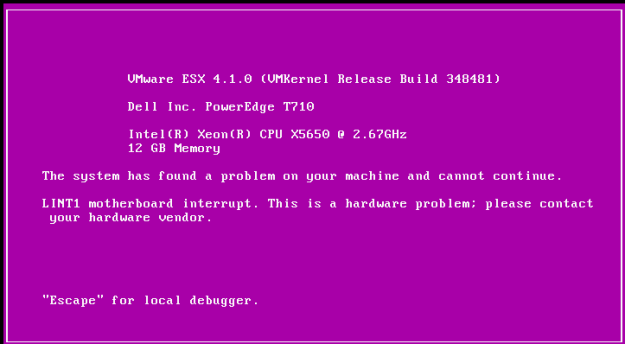
And after a reboot, an unwelcoming screen was shown:

Fortunately, after another reboot the system booted just fine, however it was pretty obvious that the hardware itself was in a pretty unstable state. On iDRAC, we have discovered that we got a critical warning on a component (unfortunately it was late at night and I didn’t think about screenshotting that) with Bus IDs 03:0:0. Listing components via lspci revealed that the following component was sitting on the given ID:
03:00.0 RAID bus controller: LSI Logic / Symbios Logic MegaRAID SAS GEN2 Controller (rev 05)
Even if it was straightforward from the get-go which component might have been failing, it was double-confirmed by the very useful lspci command.
